
[ad_1]
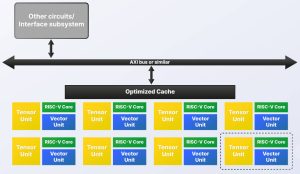
Invece di avere sullo stesso circuito integrato una CPU multi-core, una GPU multi-core per l’elaborazione vettoriale e un processore neurale multi-core per l’elaborazione tensoriale, si consigliano più istanze di un blocco costituito da un RISC a 64 bit fuori ordine -V CPU, un’unità vettoriale RVV1.0 fuori ordine (simile a GPU) con da 4 a 32 sottounità FMAC e un’unità tensore (simile a NPU) per il ridimensionamento dei dati BF16, FP16 e INT8 tra , 0,25 e 2Top/s (8bit).
“I dati sono nei registri vettoriali e possono essere utilizzati dall’unità vettoriale o dall’unità tensore con ciascuna parte che attende semplicemente a turno di accedere alla stessa posizione secondo necessità”, ha affermato Roger Espasa, CEO di Semidynamics. “Pertanto, la latenza di comunicazione è pari a zero e le cache sono ridotte al minimo.”
A ciò aggiunge la propria tecnologia bus in grado di sostenere l’accesso DRAM “oltre 50 byte/ciclo”.
“L’unità tensore fornisce la capacità di moltiplicazione della matrice per le convoluzioni, mentre l’unità vettoriale, con la sua programmabilità generale, può affrontare qualsiasi livello di attivazione odierno così come qualsiasi cosa la comunità del software AI possa sognare in futuro”, secondo l’azienda. “Tutti gli elementi di elaborazione necessari per soddisfare le esigenze dell’applicazione possono essere riuniti su un singolo chip. Esiste un solo fornitore IP, un set di istruzioni RISC-V e una catena di strumenti”.
Vede l’architettura scalare tra 0,25 Top/s e centinaia di Top/s, e afferma che ottiene un punteggio di 33,03 frame/s sul benchmark Yolo a 1 GHz con uno dei core ATV4 RISC-V dell’azienda, più un’unità vettoriale, più un unità tensore bf16.
È disponibile uno strumento di “configurazione” per proporre un equilibrio appropriato di unità tensoriali e vettoriali.
Come è possibile suddividere le attività tra più unità di elaborazione?
“Per le attività di intelligenza artificiale, ONNX RunTime è in grado di suddividere il calcolo tra molti elementi AI”, ha dichiarato l’azienda a Electronics Weekly. “Per altri ambiti, come il calcolo ad alte prestazioni, è possibile utilizzare la tecnologia di parallelizzazione del compilatore standard – openMP o MPI – per dividere il lavoro”.
Sarà disponibile il supporto dell’hypervisor per la containerizzazione e l’elaborazione crittografica.
Maggiori dettagli presso lo stand 5-337 all’Embedded World la prossima settimana a Norimberga.
[ad_2]
Source link
