
[ad_1]
Astratto
Ogni giorno su Roblox, 65.5 milioni di utenti interagiscono con milioni di esperienze, per un totale di 14,0 miliardi di ore trimestrali. Questa interazione genera un data lake su scala petabyte, che viene arricchito per scopi di analisi e machine learning (ML). Unire tabelle di fatti e dimensioni nel nostro data Lake richiede molte risorse, quindi per ottimizzare questa operazione e ridurre lo scambio di dati, abbiamo adottato i filtri Learned Bloom [1]—strutture dati intelligenti che utilizzano il machine learning. Prevedendo la presenza, questi filtri riducono considerevolmente i dati di join, migliorando l’efficienza e riducendo i costi. Nel frattempo, abbiamo anche migliorato le architetture dei nostri modelli e dimostrato i vantaggi sostanziali che offrono in termini di riduzione delle ore di memoria e CPU per l’elaborazione, nonché di aumento della stabilità operativa.
introduzione
Nel nostro data Lake, le tabelle dei fatti e i cubi di dati sono partizionati temporaneamente per un accesso efficiente, mentre le tabelle delle dimensioni non dispongono di tali partizioni e unirle alle tabelle dei fatti durante gli aggiornamenti richiede un utilizzo intensivo delle risorse. Lo spazio chiave dell’unione è determinato dalla partizione temporale della tabella dei fatti da unire. Le entità dimensione presenti in quella partizione temporale sono un piccolo sottoinsieme di quelle presenti nell’intero set di dati dimensione. Di conseguenza, la maggior parte dei dati relativi alle dimensioni mescolati in questi join alla fine verrà eliminata. Per ottimizzare questo processo e ridurre i mescolamenti inutili, abbiamo considerato l’utilizzo Filtri Bloom su chiavi di join distinte, ma ha dovuto affrontare problemi relativi alle dimensioni del filtro e all’ingombro della memoria.
Per affrontarli, abbiamo esplorato Filtri Bloom appresi, una soluzione basata su ML che riduce le dimensioni del filtro Bloom mantenendo bassi tassi di falsi positivi. Questa innovazione migliora l’efficienza delle operazioni di join riducendo i costi computazionali e migliorando la stabilità del sistema. Lo schema seguente illustra i processi di join convenzionali e ottimizzati nel nostro ambiente di calcolo distribuito.
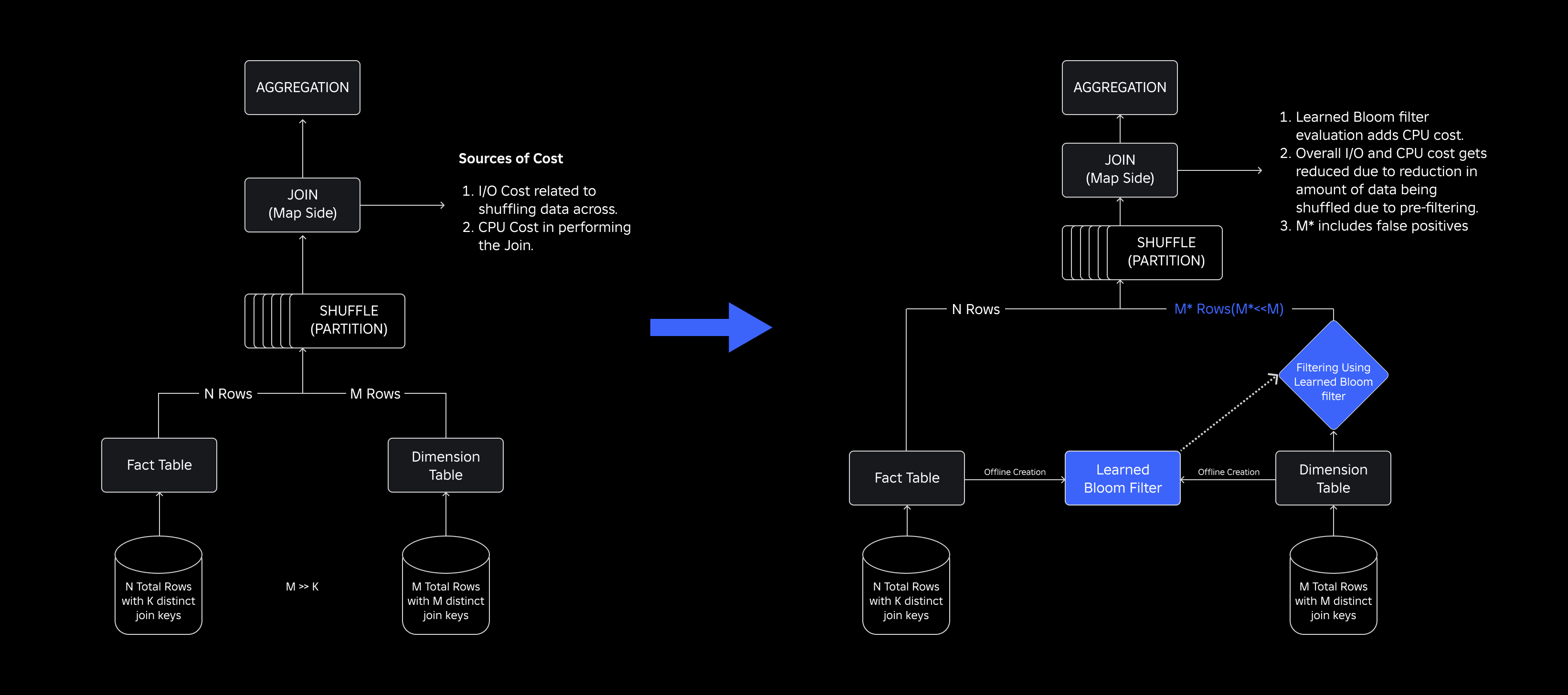
Migliorare l’efficienza del join con i filtri Bloom appresi
Per ottimizzare l’unione tra tabelle dei fatti e delle dimensioni, abbiamo adottato l’implementazione del filtro Learned Bloom. Abbiamo costruito un indice dalle chiavi presenti nella tabella dei fatti e successivamente abbiamo distribuito l’indice per prefiltrare i dati sulle dimensioni prima dell’operazione di unione.
Evoluzione dai filtri Bloom tradizionali ai filtri Bloom appresi
Sebbene un filtro Bloom tradizionale sia efficiente, aggiunge il 15-25% di memoria aggiuntiva per nodo di lavoro che deve essere caricato per raggiungere il tasso di falsi positivi desiderato. Ma sfruttando i filtri Learned Bloom, abbiamo ottenuto una dimensione dell’indice notevolmente ridotta mantenendo lo stesso tasso di falsi positivi. Ciò è dovuto alla trasformazione del Bloom Filter in un problema di classificazione binaria. Le etichette positive indicano la presenza di valori nell’indice, mentre le etichette negative indicano che sono assenti.
L’introduzione di un modello ML facilita il controllo iniziale dei valori, seguito da un filtro Bloom di backup per eliminare i falsi negativi. Le dimensioni ridotte derivano dalla rappresentazione compressa del modello e dal numero ridotto di chiavi richieste dal Bloom Filter di backup. Questo lo distingue dall’approccio convenzionale del Bloom Filter.
Come parte di questo lavoro, abbiamo stabilito due parametri per valutare il nostro approccio Learned Bloom Filter: la dimensione finale dell’oggetto serializzato dell’indice e il consumo della CPU durante l’esecuzione delle query di join.
Affrontare le sfide dell’implementazione
La nostra sfida iniziale consisteva nell’affrontare un set di dati di addestramento altamente distorto con poche chiavi della tabella dimensionale nella tabella dei fatti. In tal modo, abbiamo osservato una sovrapposizione di circa una chiave su tre tra le tabelle. Per affrontare questo problema, abbiamo sfruttato l’approccio Sandwich Learned Bloom Filter [2]. Questo integra un tradizionale filtro Bloom iniziale per riequilibrare la distribuzione del set di dati rimuovendo la maggior parte delle chiavi mancanti dalla tabella dei fatti, eliminando di fatto i campioni negativi dal set di dati. Successivamente, solo le chiavi incluse nel Bloom Filter iniziale, insieme ai falsi positivi, venivano inoltrate al modello ML, spesso definito “oracolo appreso”. Questo approccio ha prodotto un set di dati di addestramento ben bilanciato per l’oracolo appreso, superando in modo efficace il problema dei bias.
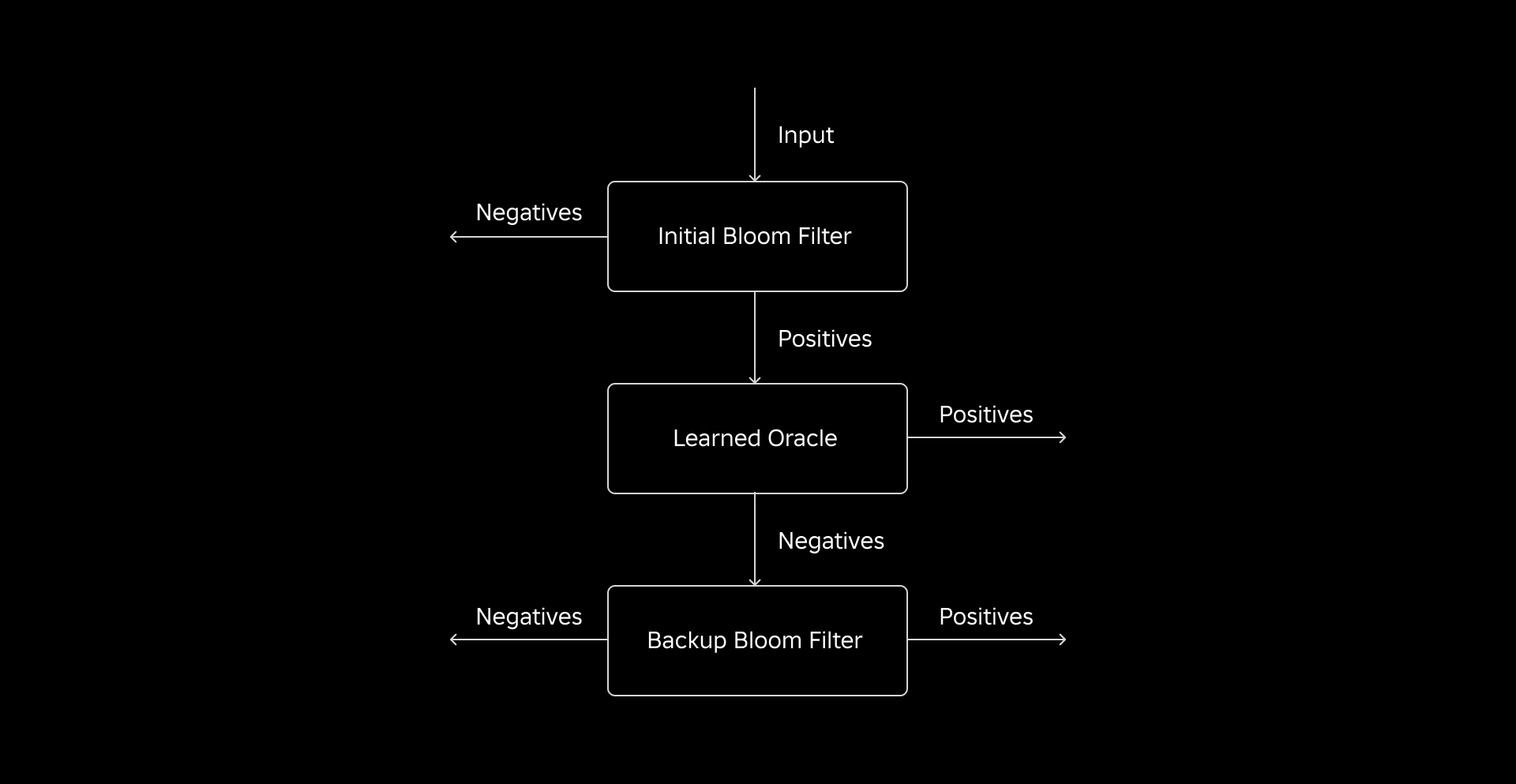
La seconda sfida era incentrata sull’architettura del modello e sulle caratteristiche di formazione. A differenza del classico problema degli URL di phishing [1], le nostre chiavi di unione (che nella maggior parte dei casi sono identificatori univoci per utenti/esperienze) non erano intrinsecamente informative. Ciò ci ha portato a esplorare gli attributi delle dimensioni come potenziali caratteristiche del modello che possono aiutare a prevedere se un’entità dimensione è presente nella tabella dei fatti. Ad esempio, immagina una tabella dei fatti che contiene informazioni sulla sessione utente per esperienze in una lingua particolare. La posizione geografica o l’attributo di preferenza linguistica della dimensione utente sarebbero buoni indicatori della presenza o meno di un singolo utente nella tabella dei fatti.
La terza sfida, la latenza dell’inferenza, richiedeva modelli che riducessero al minimo i falsi negativi e fornissero risposte rapide. Un modello ad albero con gradiente potenziato è stata la scelta ottimale per questi parametri chiave e ne abbiamo ridotto il set di funzionalità per bilanciare precisione e velocità.
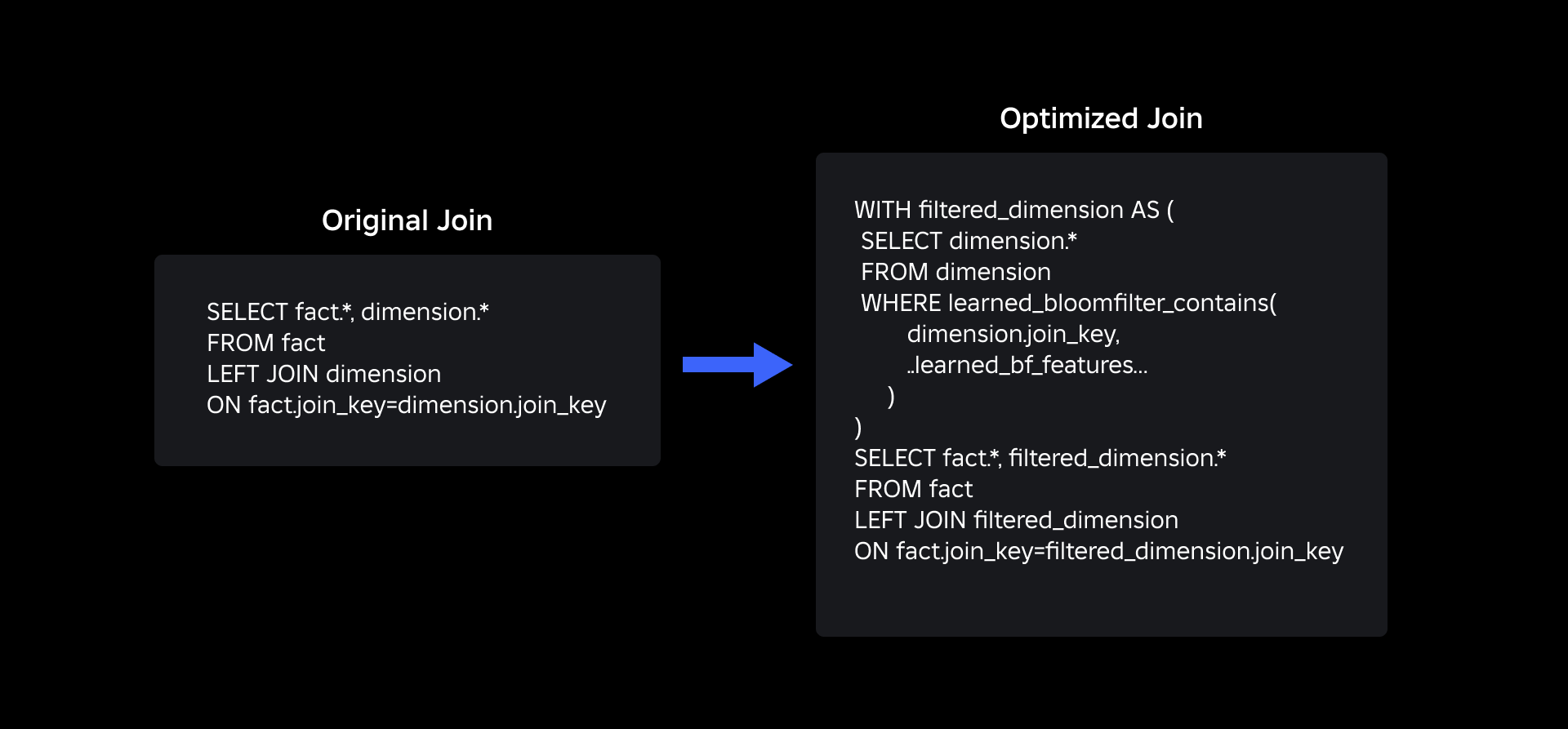
La nostra query di join aggiornata utilizzando i filtri Bloom appresi è come mostrata di seguito:
Risultati
Ecco i risultati dei nostri esperimenti con i filtri Learned Bloom nel nostro data Lake. Li abbiamo integrati in cinque carichi di lavoro di produzione, ciascuno dei quali possedeva caratteristiche di dati diverse. La parte più costosa dal punto di vista computazionale di questi carichi di lavoro è l’unione tra una tabella dei fatti e una tabella delle dimensioni. Lo spazio chiave delle tabelle dei fatti è circa il 30% della tabella delle dimensioni. Per cominciare, discutiamo di come il Learned Bloom Filter abbia sovraperformato i tradizionali Bloom Filter in termini di dimensione finale dell’oggetto serializzato. Successivamente, mostriamo i miglioramenti delle prestazioni che abbiamo osservato integrando i filtri Learned Bloom nelle nostre pipeline di elaborazione del carico di lavoro.
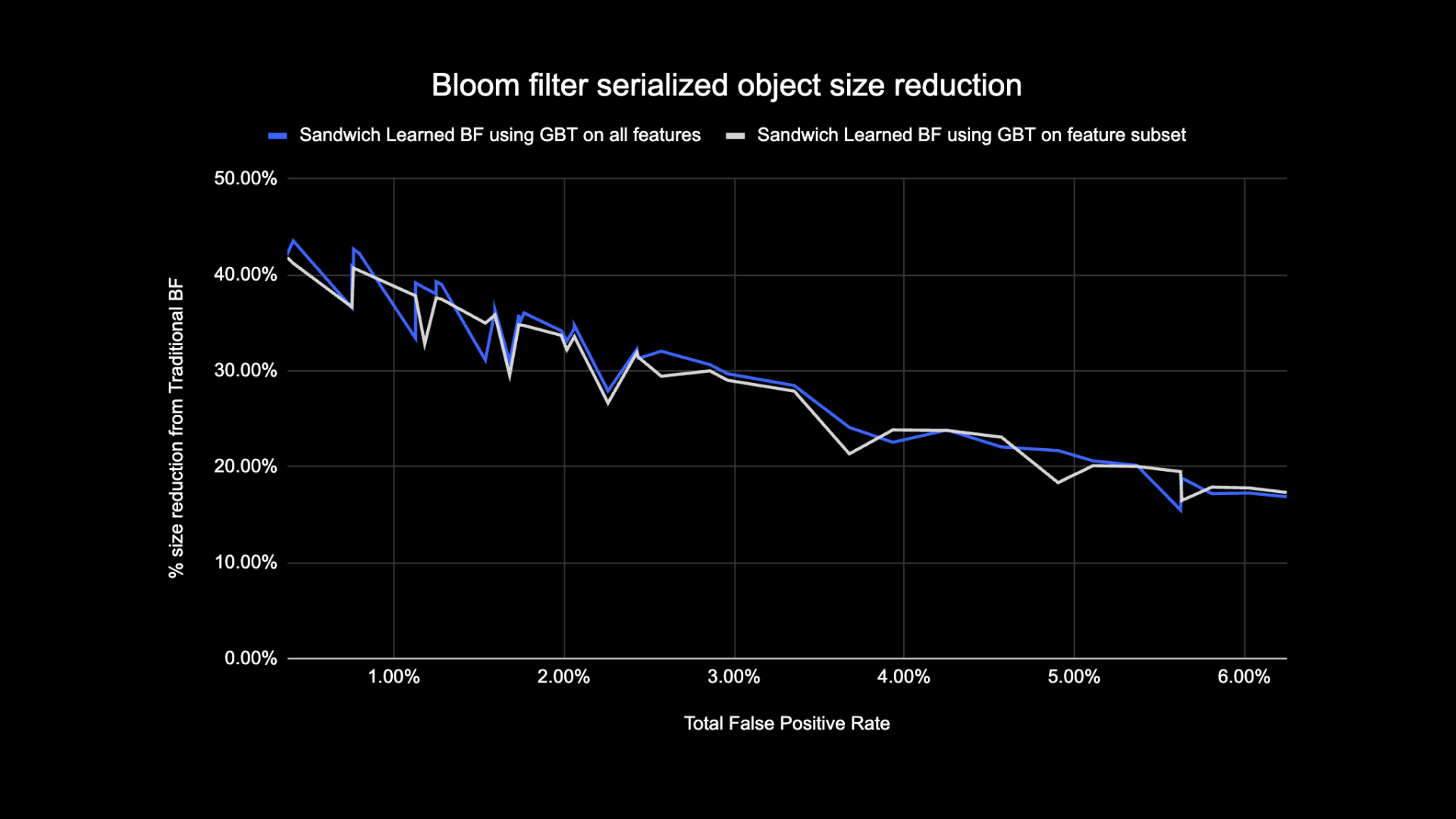
Confronto delle dimensioni del filtro Bloom appreso
Come mostrato di seguito, osservando un dato tasso di falsi positivi, le due varianti del filtro Bloom appreso migliorano la dimensione totale dell’oggetto tra il 17 e il 42% rispetto ai tradizionali filtri Bloom.
Inoltre, utilizzando un sottoinsieme più piccolo di funzionalità nel nostro modello basato su albero con gradiente potenziato, abbiamo perso solo una piccola percentuale di ottimizzazione rendendo l’inferenza più veloce.
Risultati appresi sull’utilizzo del filtro Bloom
In questa sezione confrontiamo le prestazioni dei join basati su Bloom Filter con quelle dei join regolari attraverso diversi parametri.
La tabella seguente confronta le prestazioni dei carichi di lavoro con e senza l’uso dei filtri Learned Bloom. Un filtro Bloom appreso con una probabilità totale di falsi positivi dell’1% dimostra il confronto riportato di seguito mantenendo la stessa configurazione del cluster per entrambi i tipi di join.

Innanzitutto, abbiamo riscontrato che l’implementazione del filtro Bloom ha sovraperformato il join normale fino al 60% in termini di ore di CPU. Abbiamo riscontrato un aumento nell’utilizzo della CPU nella fase di scansione per l’approccio Learned Bloom Filter a causa del calcolo aggiuntivo impiegato nella valutazione del Bloom Filter. Tuttavia, il prefiltraggio eseguito in questa fase ha ridotto la dimensione dei dati mescolati, contribuendo a ridurre la CPU utilizzata dalle fasi downstream, riducendo così le ore totali di CPU.
In secondo luogo, i filtri Learned Bloom hanno circa l’80% in meno di dimensioni totali dei dati e circa l’80% in meno di byte shuffle totali scritti rispetto a un normale join. Ciò porta a prestazioni di join più stabili, come discusso di seguito.
Abbiamo riscontrato anche un utilizzo ridotto delle risorse negli altri carichi di lavoro di produzione in fase di sperimentazione. Nell’arco di due settimane per tutti e cinque i carichi di lavoro, l’approccio Learned Bloom Filter ha generato una media risparmio sui costi giornalieri Di 25%, che tiene conto anche dell’addestramento del modello e della creazione dell’indice.
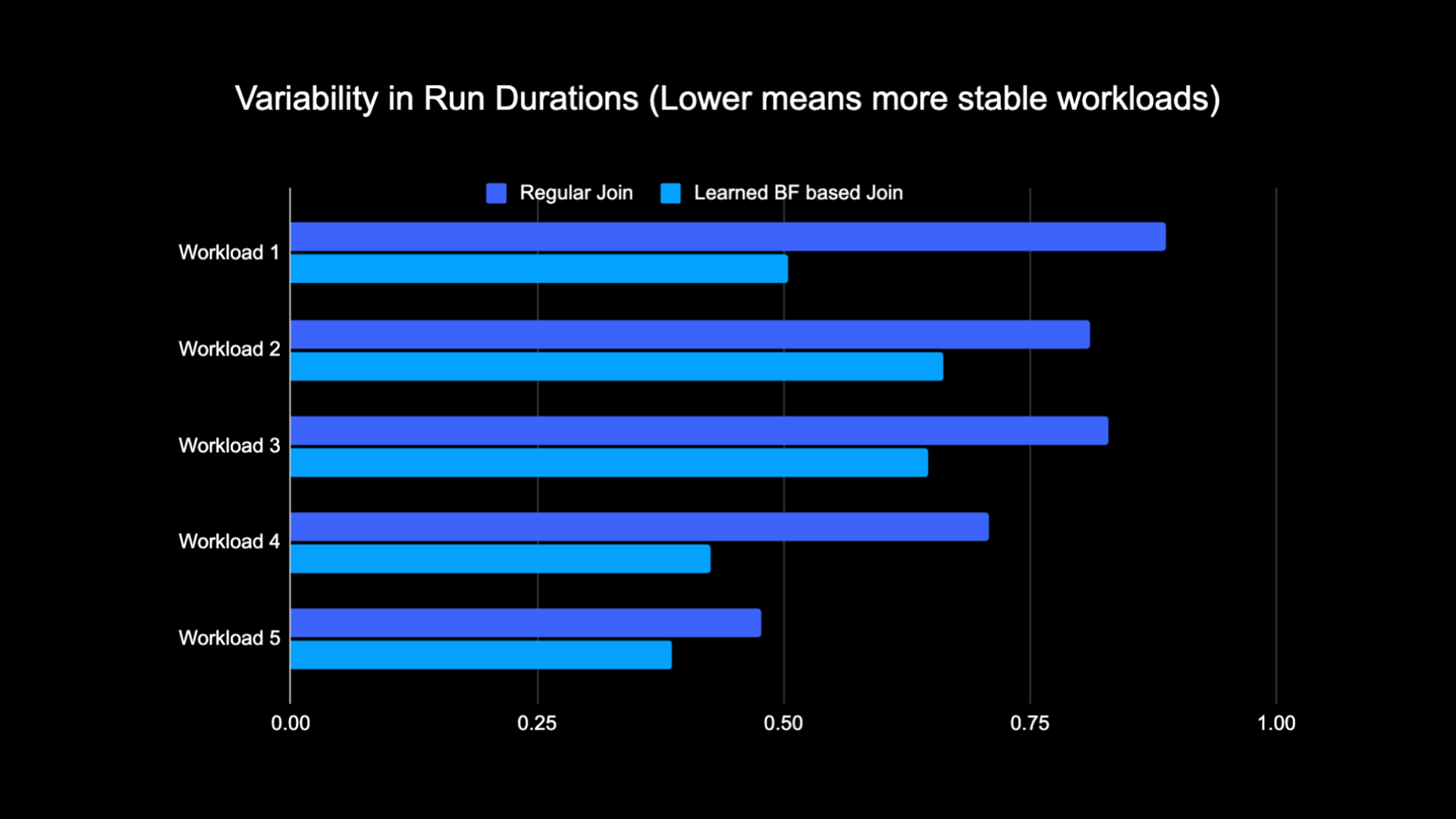
Grazie alla ridotta quantità di dati mescolati durante l’esecuzione dell’unione, siamo stati in grado di ridurre significativamente i costi operativi della nostra pipeline di analisi rendendola allo stesso tempo più stabile. Il grafico seguente mostra la variabilità (utilizzando un coefficiente di variazione) nelle durate di esecuzione (muro ora dell’orologio) per un carico di lavoro di join regolare e un carico di lavoro basato sul filtro Learned Bloom per un periodo di due settimane per i cinque carichi di lavoro che abbiamo sperimentato. Le esecuzioni che utilizzano i filtri Learned Bloom sono risultate più stabili, ovvero più costanti nella durata, il che apre la possibilità di spostarle su risorse di calcolo temporanee e inaffidabili più economiche.
Riferimenti
[1] T. Kraska, A. Beutel, EH Chi, J. Dean e N. Polyzotis. Il caso delle strutture di indici apprese. https://arxiv.org/abs/1712.012082017.
[2] M. Mitzenmacher. Ottimizzazione dei filtri Bloom appresi tramite sandwich.
https://arxiv.org/abs/1803.014742018.
¹A 3 mesi terminati il 30 giugno 2023
²A 3 mesi terminati il 30 giugno 2023
[ad_2]
Source link
